Darstellung
Text Completion (OpenAI Text Completion)
Überblick
Mit dem Baustein Text Completion stellst du eine Verbindung zur Open AI Schnittstelle her, darüber kannst Prompts an Open AI übertragen und KI-generierte Texte zurückerhalten.
Wird der Baustein im Workflow verwendet, erhält der Baustein standardmäßig einen generisch beschreibenden Namen: Text Completion wird zu OpenAI Text Completion.
Den Baustein findest du unter: Workflow-Baukasten → DO → Services → Integrations → OpenAI
Beispiel
Anhand der bestehenden Produktinformationen möchtest du automatisiert Produktbeschreibungen erstellen.
Konfigurationsoptionen
Der Baustein hat folgende Konfigurationsoptionen:
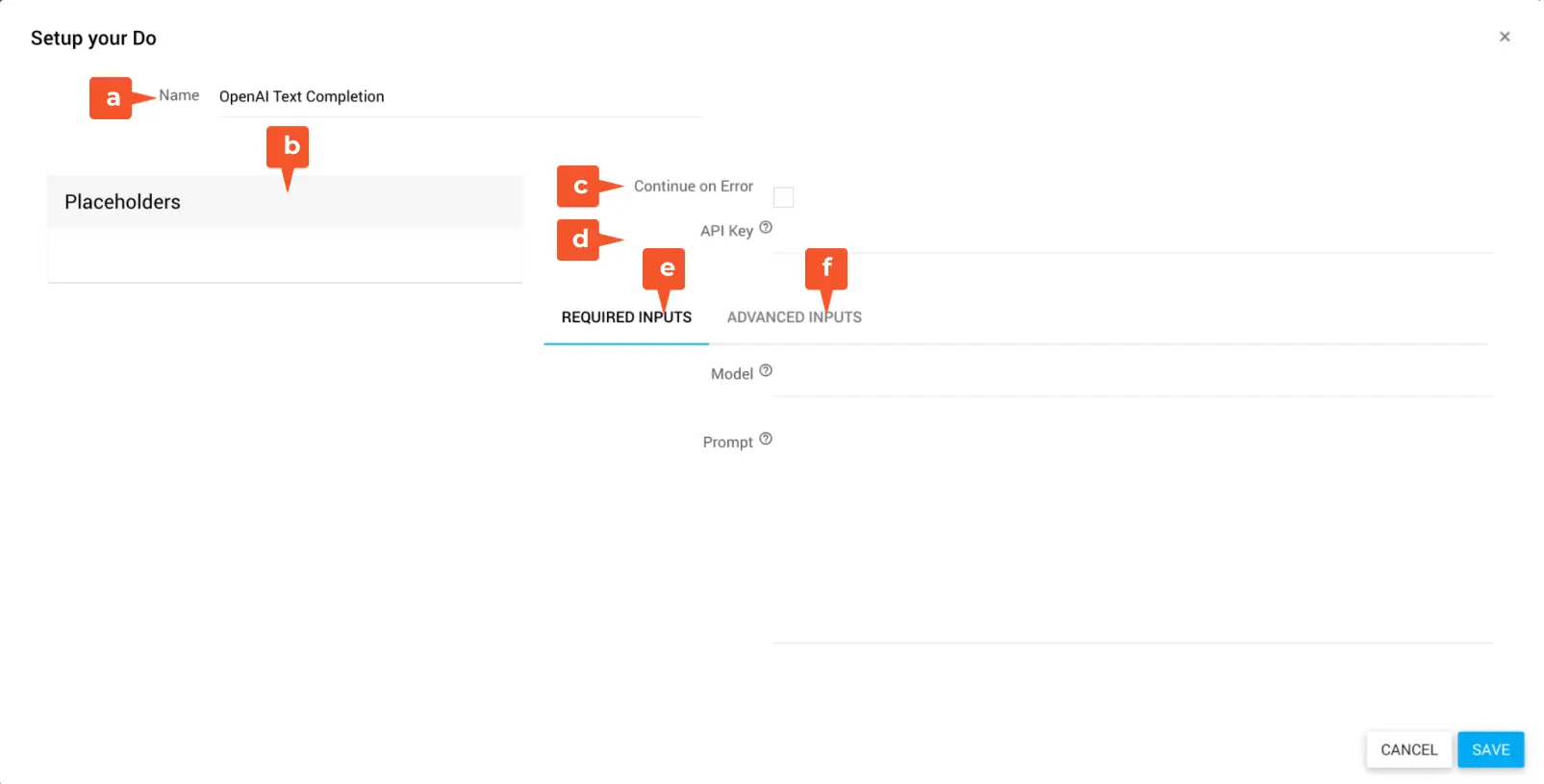
Name: Bezeichnung des Bausteins
Placeholders: Liste der verfügbaren Platzhalter
Continue on Errors: Wenn aktiviert, läuft der Workflow trotz einer Fehlermeldung des HTTP-Statuscodes (400, 500) der Gegenstelle weiter und wird nicht abgebrochen
API Key: API-Key deines OpenAI Kontos
Required Inputs: Pflichtangaben des Bausteins
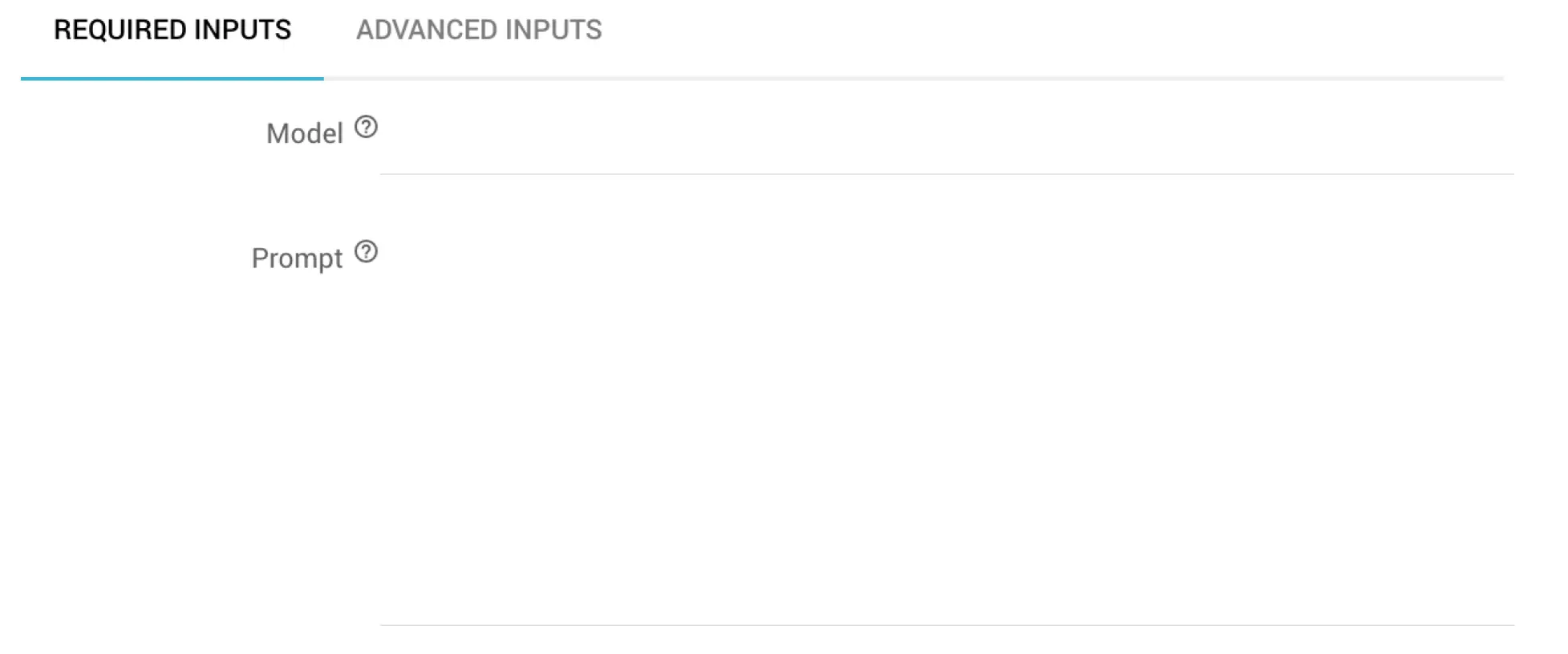
- Model: ID des OpenAI-Sprachmodells, welches verwendet werden soll. z.B. gpt-4 oder gpt-3.5-turbo. Die möglichen Sprachmodelle kannst du der OpenAI-Dokumentation entnehmen
- Prompt: Input für den Prompt, der an das Sprachmodell geschickt werden soll
- Advanced Inputs: Erweiterte Konfigurationsoptionen des Bausteins
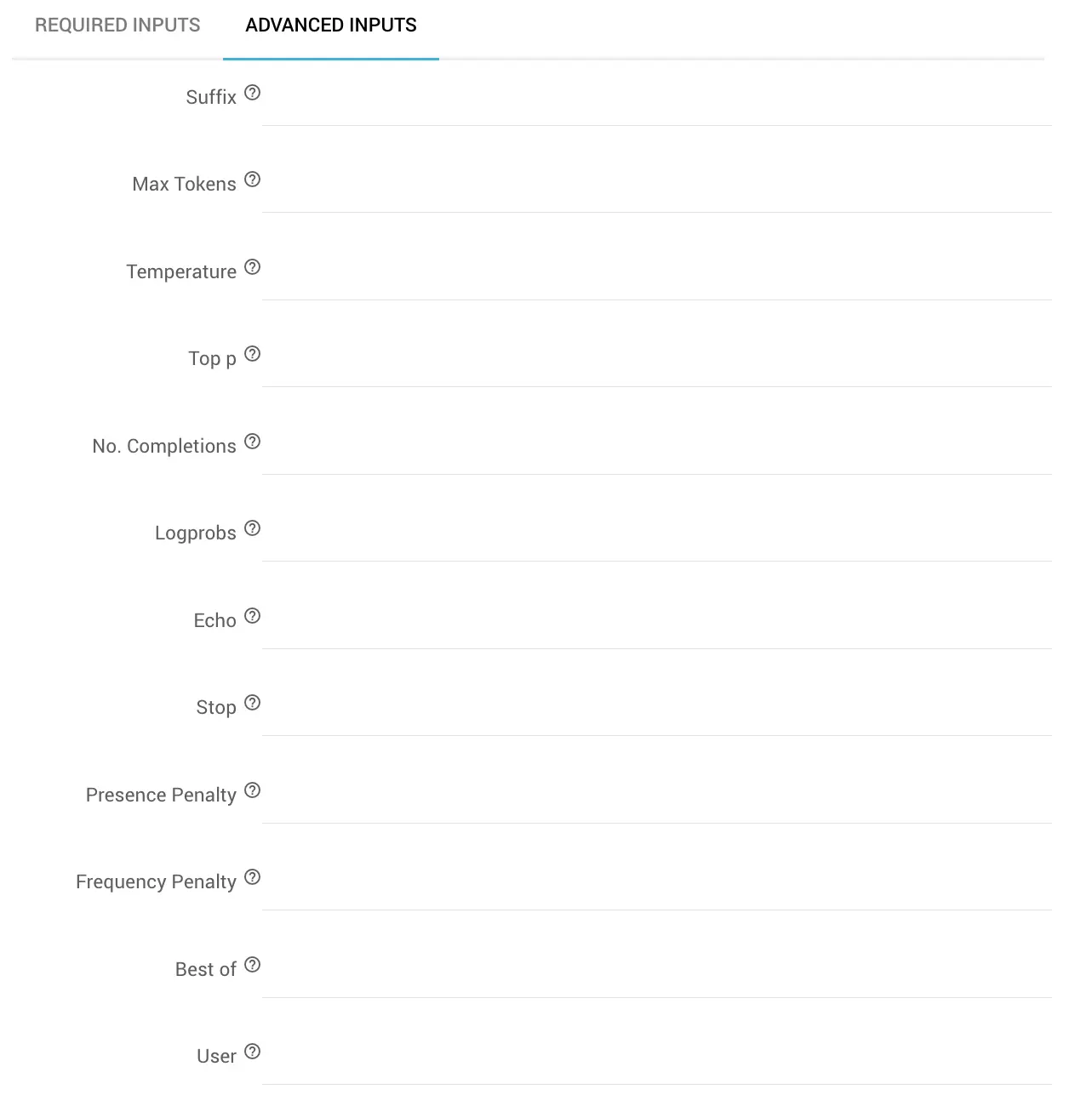
- Suffix: Suffix nach Abschluss des generierten Textes
- Max Tokens: Die maximale Anzahl von Tokens, die bei der Texterstellung erzeugt werden. (Die Tokenmenge des Inputs + der Wert von Max Tokens, darf die Kontextlänge des Sprachmodells nicht übersteigen)
- Der Standardwert liegt bei 16
- Temperature: Bestimmt anhand eines Dezimalwerts zwischen 0 und 2die Genauigkeit der Antwort, also wie sehr die KI halluzinieren darf bzw. wie kreativ oder fokussiert die KI-Antwort ausfallen soll
- Der Standardwert liegt bei 1
- Niedrigere Werte wie 0.2 führen zu bestimmteren, fokussierteren Antworten
- Höhere Werte wie 1.5 führen zu zufälligeren, kreativeren Antworten
- Bei Anpassungen der Genauigkeit empfiehlt OpenAI allgemein diesen Wert, oder die Top p zu ändern, aber nicht beides zusammen
- Top p: Dezimalwert als Variable des sogenannten "Nucleus Sampling" als Alternative zur Genauigkeitssteuerung über Temperature. Im "Nucleus Sampling" berücksichtigt das Sprachmodell die Ergebnisse der Token anhand der Wahrscheinlichkeitsmasse, die durch den Wert in Top p definiert wird. z.B. bedeutet ein **Top p-**Wert von 0.1, dass nur die Token berücksichtigt werden, welche die oberen 10% der Wahrscheinlichkeitsmaße enthalten
- Der Standardwert liegt bei 1
- Bei Anpassungen der Genauigkeit empfiehlt OpenAI allgemein diesen Wert, oder die Temperature zu ändern, aber nicht beides zusammen
- No. Completions: Angabe der Menge an Completions in der Antwort eines Promptes
- Der Standardwert liegt bei 1
- Hinweis: Da dieser Parameter mehrere Completions erzeugt, kann er das Token-Kontigent einer Antwort schnell aufbrauchen. Daher sollte diese Konfiguration immer mit Max Tokens und Stop abgestimmt sein.
- Logprobs: Definition der Protokollwahrscheinlichkeiten für die wahrscheinlichsten Token ebenso wie die der ausgewählten Token. Das bedeutet, wenn der Wert bei 5 liegt, gibt die API eine Liste der 5 wahrscheinlichsten Token zurück. Die API gibt immer den Logprobs-Wert des gesampelten Tokens zurück. Demnach kann eine Antwort immer nur die in Logprobsdefinierte Menge +1 Element enthalten kann.
- Der Standardwert liegt bei null
- Der Maximalwert liegt bei 5
- Echo: Angabe, ob der ursprüngliche Prompt erneut zusammen mit der Antwort ausgegeben werden soll: true, false
- Der Standardwert ist false
- Stop: Definition von bis zu 4 Sequenzen (als String, Array, Null), an denen keine weiteren Token mehr durch die API erzeugt werden. Der in der Antwort zurückgegebene Wert enthält die Stoppsequenz nicht mehr.
- Der Standardwert liegt bei null
- Presence Penalty: Bestimmt anhand eines Dezimalwerts zwischen -2 und 2, mit welcher Wahrscheinlichkeit das Sprachmodell über neue Themen spricht. Positive Werte prüfen, ob Token bereits in der Antwort enthalten sind und sanktionieren neue Token anhand des eingetragenen Wertes, sodass das Modell mit erhöhter Wahrscheinlichkeit über neue Themen sprechen wird.
- Der Standardwert liegt bei 0
- Frequency Penalty: Bestimmt anhand eines Dezimalwerts zwischen -2 und 2, mit welcher Wahrscheinlichkeit sich das Sprachmodell wortwörtlich wiederholt. Positive Werte prüfen, die bisherige Häufigkeit eines Token in der Antwort und sanktionieren neue Token anhand des eingetragenen Wertes, sodass das Modell sich mit einer niedrigeren Wahrscheinlichkeit wortwörtlich wiederholt.
- Der Standardwert liegt bei 0
- Best of: Anhand des Werts wird server-seitig eine Auswahl der "besten" Completion-Ergebnisse einer Antwort getroffen (diejenigen mit der höchsten Logprob-Wert je Token).
- Der Standardwert liegt bei 1. Demnach wird die beste Auswahl ausgespielt. Ist der Wert 2, werden die beiden besten ausgewählt.
- Im Zusammenspiel mit No. Completions steuert Best of die Anzahl der bestmöglichen Completions und No. Completions gibt an, wie viele Completions dieser Auswahl mit der Antwort zurückgegeben werden sollen.
- Hinweis: Da dieser Parameter mehrere Completions erzeugt, kann er das Token-Kontigent einer Antwort schnell aufbrauchen. Daher sollte diese Konfiguration immer mit Max Tokens und Stop abgestimmt sein.
- User: Die UserID des Verwenders
- Die Verwendung einer UserID kann hilfreich sein, Missbrauch zu überwachen und aufzudecken.
Output des Bausteins
Im weiteren Verlauf des Workflows steht dir der Output des OpenAI Text Completion-Bausteins zur Verfügung.
Der Output entspricht der API-Response der OpenAI-Schnittstelle und besteht aus folgenden Elementen:
- Response Item: Rückgabe-Objekt der Text Completion
- Response Error: Rückgabe -Objekt der Fehlerdaten einer gescheiterten Anfrage
- Rückmeldung der Gegenstelle (status_code) entsprechend der HTTP Statuscodes (externer Link)
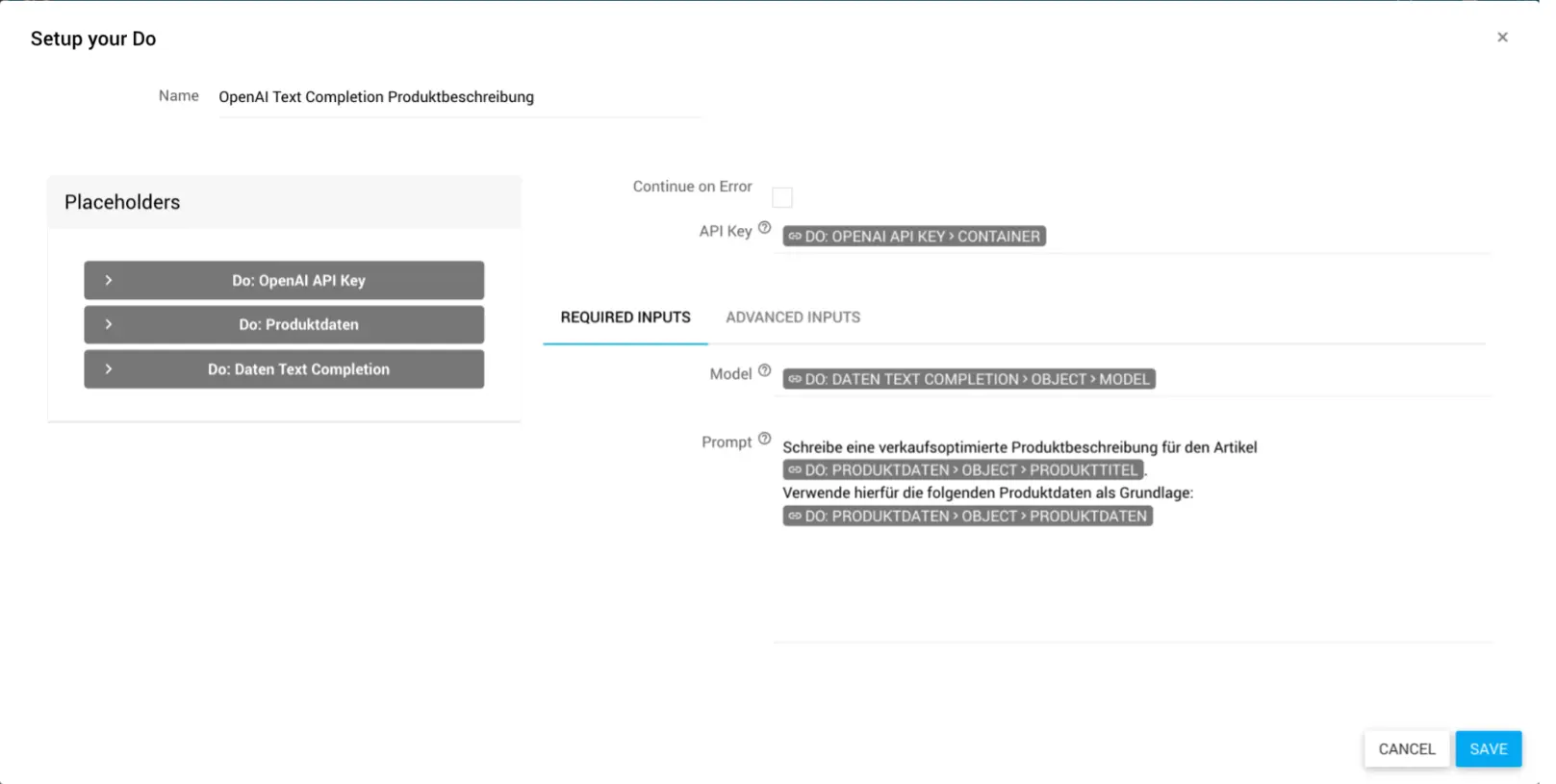
Text Completion konfigurieren
Öffne den Konfigurationsdialog des Bausteins über mehr → edit.
Gib im Feld Name eine treffende Bezeichnung ein. Zum Beispiel: „OpenAI Text Completion Produktbeschreibung“
Stelle anhand deines API Keys (String) Zugang zu deinem OpenAI-Konto her.
Definiere das zu verwendende Sprachmodell für deinen Prompt, in dem du im Required Input das Model (String) zuweist und deinen Prompt (String / Array) konfigurierst.
Hinweis
Beachte bei der Arbeit mit dem Baustein Text Completion immer das Token-Limit von Open AI. Der Umfang deines Prompts und seiner Antwort werden von der API in Token bemessen. Hierfür werden Zeichen und Zeichenketten (Worte, Wortabschnitte, Buchstaben und Zeichen) in Token umgerechnet.
Das Token-Limit (berechnet aus der Token-Summe von Prompts und Antwort) ist abhängig vom verwendeten Sprachmodell und variiert zwischen 4097 und 32768 Token. Überschreitest du das Token-Limit bricht die Antwort ab und du erhältst ggf. einen Fehler.
Mehr Informationen zu Token findest du in der OpenAI Dokumentation Die Tokenlimits der verschiedenen Modelle findest du in der Übersicht der Sprachmodelle.
- Konfiguriere die optionalen Advanced Inputs mit den Daten zu Suffix (String), Max Tokens (Integer), Temperature (Decimal), Top p (Decimal), No. Completions (Integer), Logprobs (Integer), Echo (Boolean), Stop (String), Presence Penalty (Decimal), Frequency Penalty (Decimal), Best of (Integer), User (String)

Klicke auf SAVE.
✓ Der Baustein ist konfiguriert.